Base path (return=/root/websites/) :/root/mywebsite
输入网站的URL
1
Enter URLs (separated by commas or blank spaces) :www.baidu.com
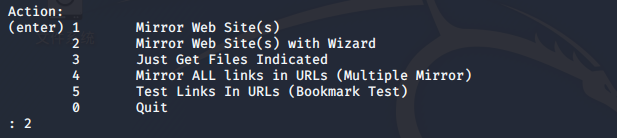
选择操作(此处选择2)
1 2 3 4 5 6 7 8
Action: (enter) 1 Mirror Web Site(s) //直接镜像站点 2 Mirror Web Site(s) with Wizard //用向导完成镜像 3 Just Get Files Indicated //只get某种特定的文件 4 Mirror ALL links in URLs (Multiple Mirror)//镜像在这个url下所有的链接 5 Test Links In URLs (Bookmark Test) //测试在这个url下的链接 0 Quit //退出 :
指定是否在实施攻击时使用代理(此处默认输入none,不使用代理)
1
Proxy (return=none) :
定义字符,爬取特定类型的数据(此处输入*表示爬取全部类型数据)
1 2
You can define wildcards, like: -*.gif +www.*.com/*.zip -*img_*.zip Wildcards (return=none) :*
设置更多选项,可以使用help查看(此处选择默认)
1 2 3
You can define additional options, such as recurse level (-r<number>), separated by blank spaces To see the option list, typehelp Additional options (return=none) :
O 镜像路径/缓存和日志文件路径 -O 镜像路径[,缓存和日志文件路径] (--path <param>)
行为选项
1 2 3 4 5
w *镜像网站 (--mirror) W 镜像网站,半自动 (asks questions) (--mirror-wizard) g 只获取文件(保存在当前目录中) (--get-files) i 使用缓存继续中断的镜像 (--continue) Y 镜像所有位于第一级页面的链接 (镜像链接) (--mirrorlinks)
C 创建/使用缓存进行更新和重试 (C0 无缓存,C1 缓存优先,* C2 测试更新前) (--cache[=N]) k 将所有文件存储在缓存中 (如果文件在磁盘上,则此功能不可用) (--store-all-in-cache) %n 不能重新下载本地删除的文件 (--do-not-recatch) %v 在屏幕上显示下载的文件名(实时) - * %v1 缩写版 - %v2 完整 (--display) Q 无日志-安静模式 (--do-not-log) q 无问题-安静模式 (--quiet) z 日志-附加信息 (--extra-log) Z 日志-debug (--debug-log) v 登录屏幕 (--verbose) f *登录文件 (--file-log) f2 一个单一日志文件(--single-log) I *编制索引 (I0 不编制索引) (--index) %i 为项目文件夹创建顶级索引 (* %i0 不创建) (--build-top-index) %I 为此镜像创建可搜索索引 (* %I0 不创建) (--search-index)
专家选项
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
pN 优先模式: (* p3) (--priority[=N]) p0 只扫描,不保存任何内容 (用于检查链接) p1 只保存html文件 p2 只保存非html文件 *p3 保存所有文件 p7 先获取html文件,然后处理其他文件 S 保持在同一个目录 (--stay-on-same-dir) D *只能进入子目录 (--can-go-down) U 只能进入父目录 (--can-go-up) B 可以上下进入目录结构 (--can-go-up-and-down) a *保持在同一地址 (--stay-on-same-address) d 保持在同一主域 (--stay-on-same-domain) l 保持相同的TLD (eg: .com) (--stay-on-same-tld) e go everywhere on the web (--go-everywhere) %H 在日志文件中调试HTTP头 (--debug-headers)
N0 站点结构 (默认) N1 HTML in web/, images/other files in web/images/ N2 HTML in web/HTML, images/other in web/images N3 HTML in web/, images/other in web/ N4 HTML in web/, images/other in web/xxx, where xxx is the file extension (all gif will be placed onto web/gif, for example) N5 Images/other in web/xxx and HTML in web/HTML N99 All files in web/, with random names (gadget !) N100 站点结构,不包括www.domain.xxx/ N101 Identical to N1 exept that "web" is replaced by the site's name N102 Identical to N2 exept that "web" is replaced by the site's name N103 Identical to N3 exept that "web" is replaced by the site's name N104 Identical to N4 exept that "web" is replaced by the site's name N105 Identical to N5 exept that "web" is replaced by the site's name N199 Identical to N99 exept that "web" is replaced by the site's name N1001 Identical to N1 exept that there is no "web" directory N1002 Identical to N2 exept that there is no "web" directory N1003 Identical to N3 exept that there is no "web" directory (option set for g option) N1004 Identical to N4 exept that there is no "web" directory N1005 Identical to N5 exept that there is no "web" directory N1099 Identical to N99 exept that there is no "web" directory