实验目的
- 通过Apache Sentry对Hadoop系统中的数据实现细粒度控制;
- 学会使用Cloudera Manager快速管理和部署Hadoop相关服务.
软件设备
软件设备
- VMware虚拟机运行程序
- cloudera-quickstart-vm-5.13.0-0 虚拟机(下载网址:https://downloads.cloudera.com/demo_vm/vmware/cloudera-quickstart-vm-5.13.0-0-vmware.zip)
硬件设备
- 可运行虚拟机的windows 10宿主机
实验原理
在未使用Sentry前,Hadoop对用户的授权是粗粒度级的,用户或者不能访问文件内的数据或者能访问整个文件的数据。Sentry可以控制用户对Hadoop中数据的访问,并对已通过验证的用户提供数据访问特权。该特权可细分到查找、插入、删除等操作的控制以及用户可查看数据库中的哪些数据。
实验内容
- 熟悉Cloudera Manager,并在系统中部署Apache Sentry服务;
- 使用Apache Sentry对数据库实现简单的授权管理;
实验步骤
Apache Sentry安装步骤
使用vmware打开cloudera-quickstart-vm-5.13.0-0 虚拟机文件并调整虚拟机参数如下;

进入系统后打开终端,输入
sudo /home/cloudera/cloudera-manager --force --express命令,等待cloudera manager启动。出现Username: cloudera和Password: cloudera表明Cloudera Manager启动成功;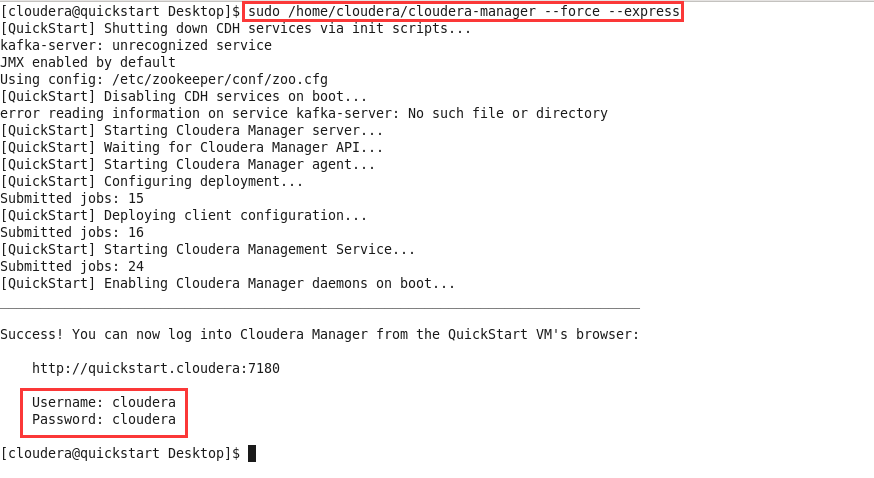
点击浏览器书签栏的Cloudera Manager书签,网页载入完毕后会弹出提示信息,点击
I Agree,输入之前获取的用户名和密码进入图形化管理界面;
切换到终端,输入
mysql -u root -p进入数据库,密码为上一步的cloudera;
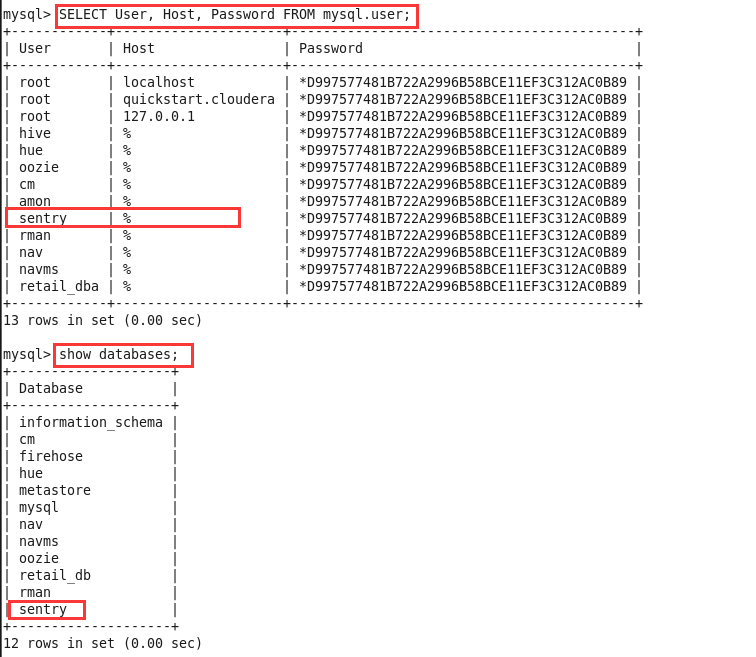
进入数据库后,通过命令删除sentry@’%’用户以及sentry数据库;
删除前
删除


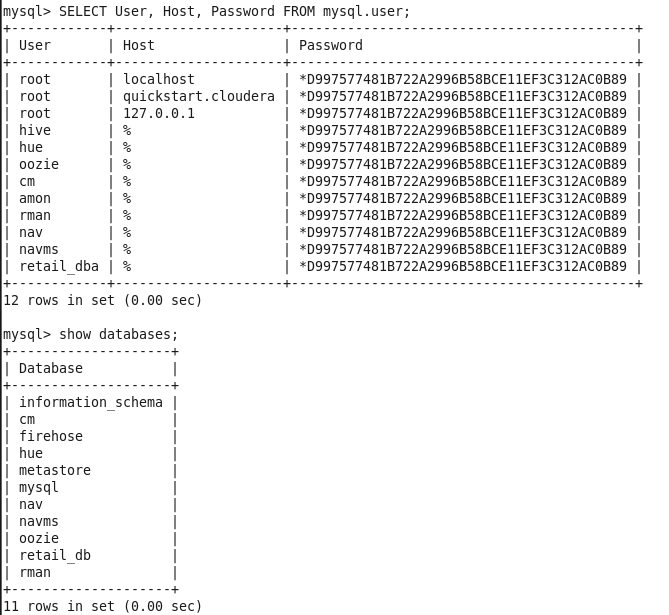
删除后
然后重新创建sentry用户和sentry数据库,并对新创建的sentry用户赋予对sentry数据库的全部操作权限;
1
2
3
4create user sentry identified by 'sentry123456';
grant all on sentry.* to sentry@'localhost' identified by 'sentry123456';
grant all on sentry.* to sentry@'%' identified by 'sentry123456';
create database sentry;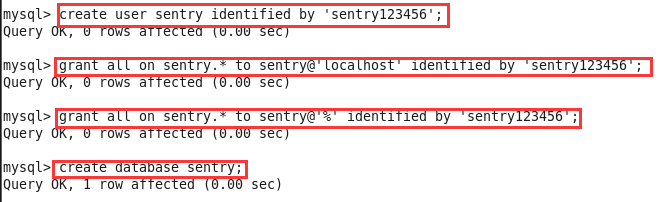
切换到浏览器中Cloudera Manager管理界面,点击左侧管理面板的小三角,选择
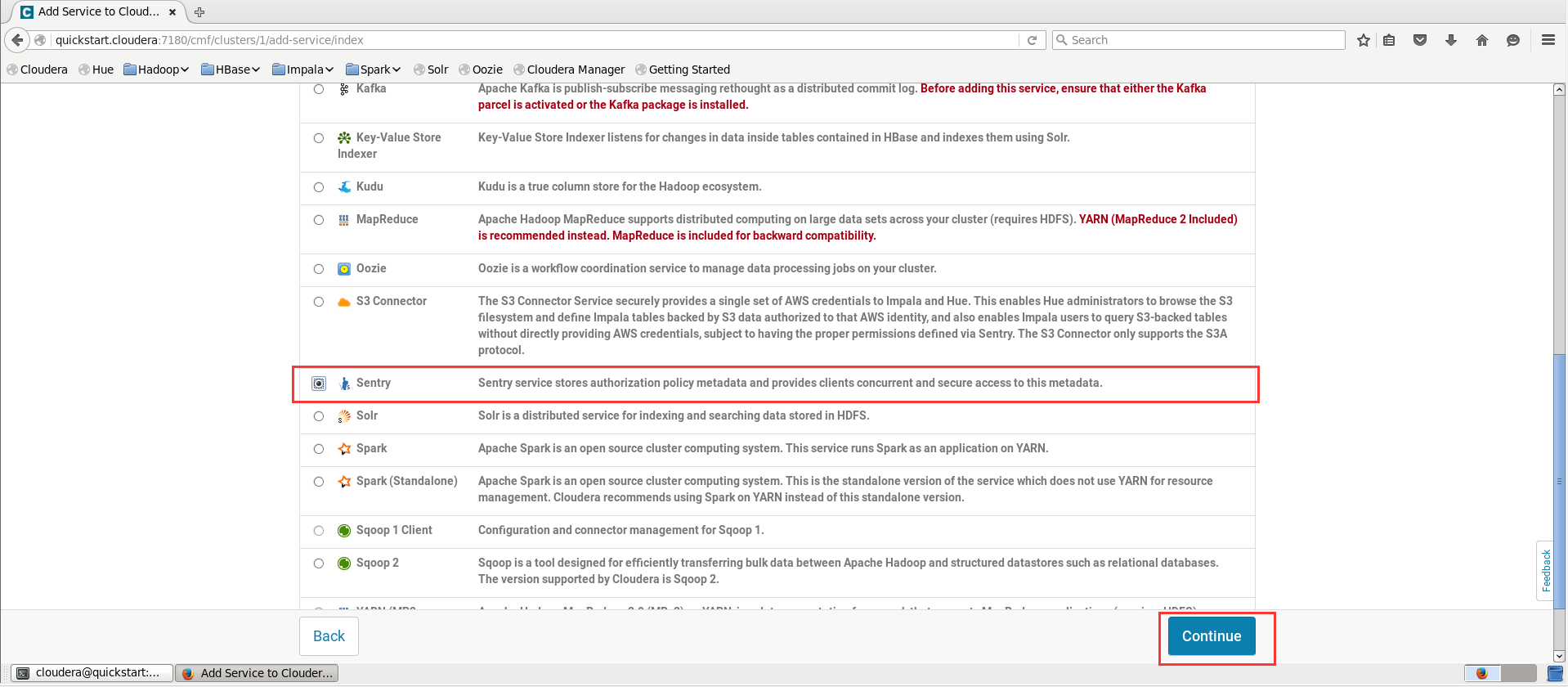
Add Service,下拉选择Sentry,点击Continue;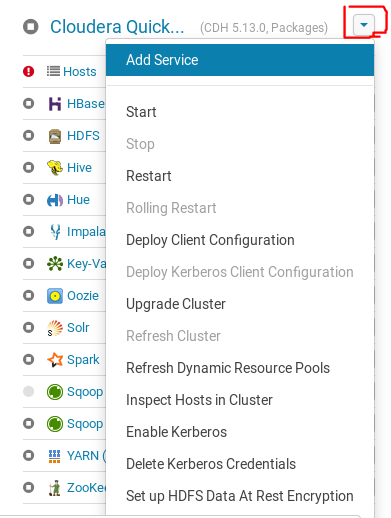
到达Customize Role assignments for Sentry界面后不进行修改,点击
Continue;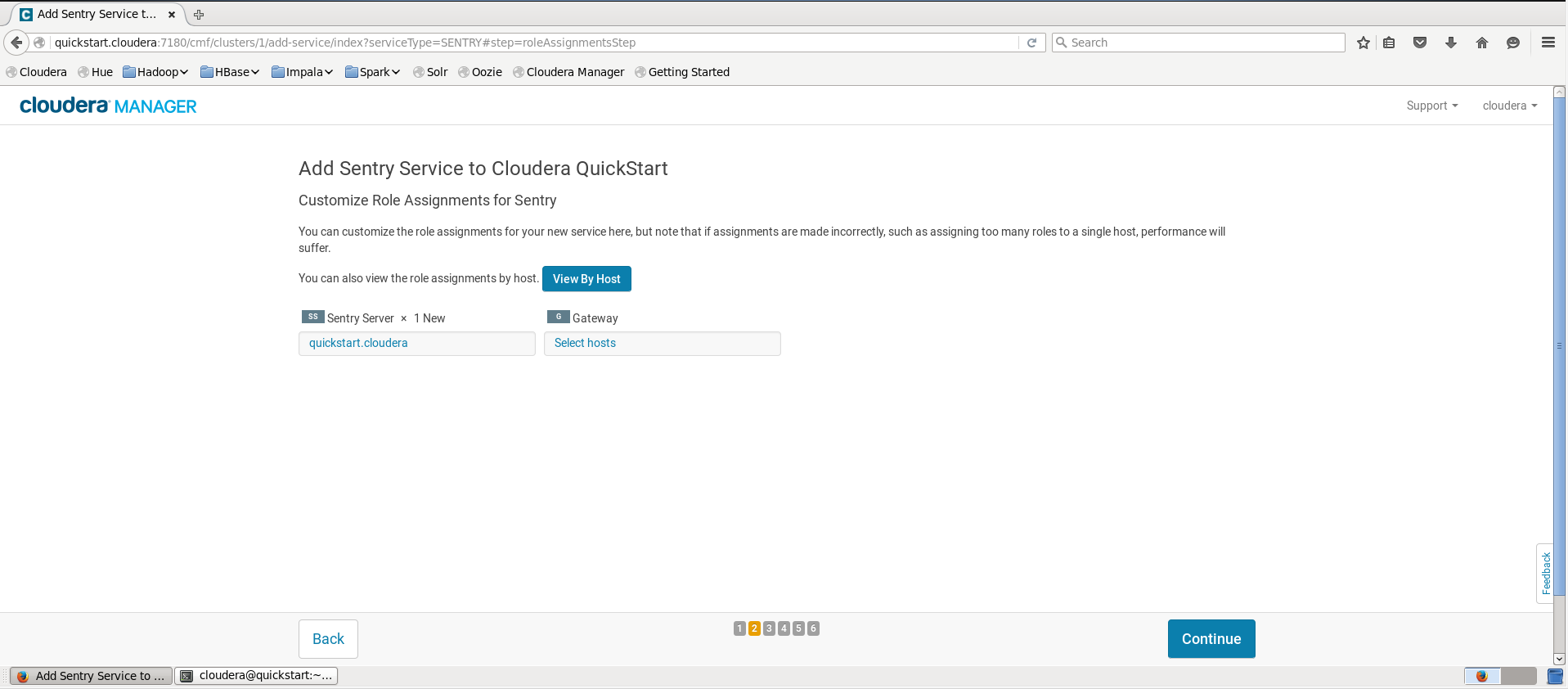
到达Database Setup部分,输入前面步骤中设置的sentry数据库名称“sentry”、用户名以及密码,并点击
Test Connection确保可连接;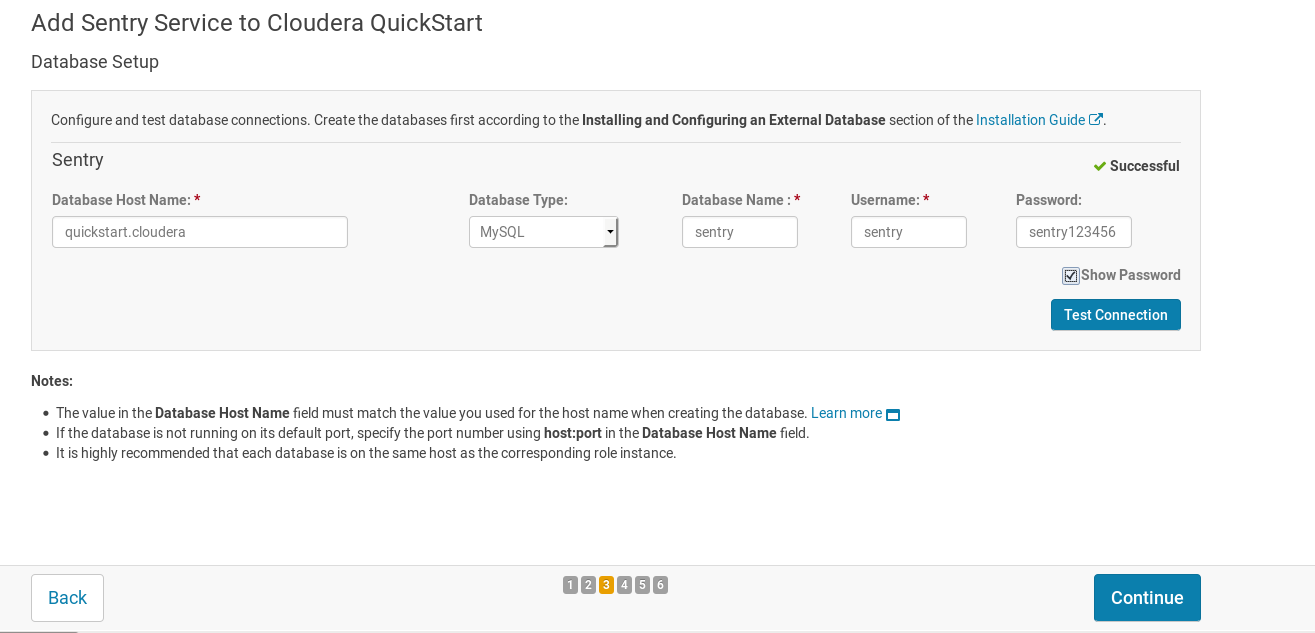
完成后,点击
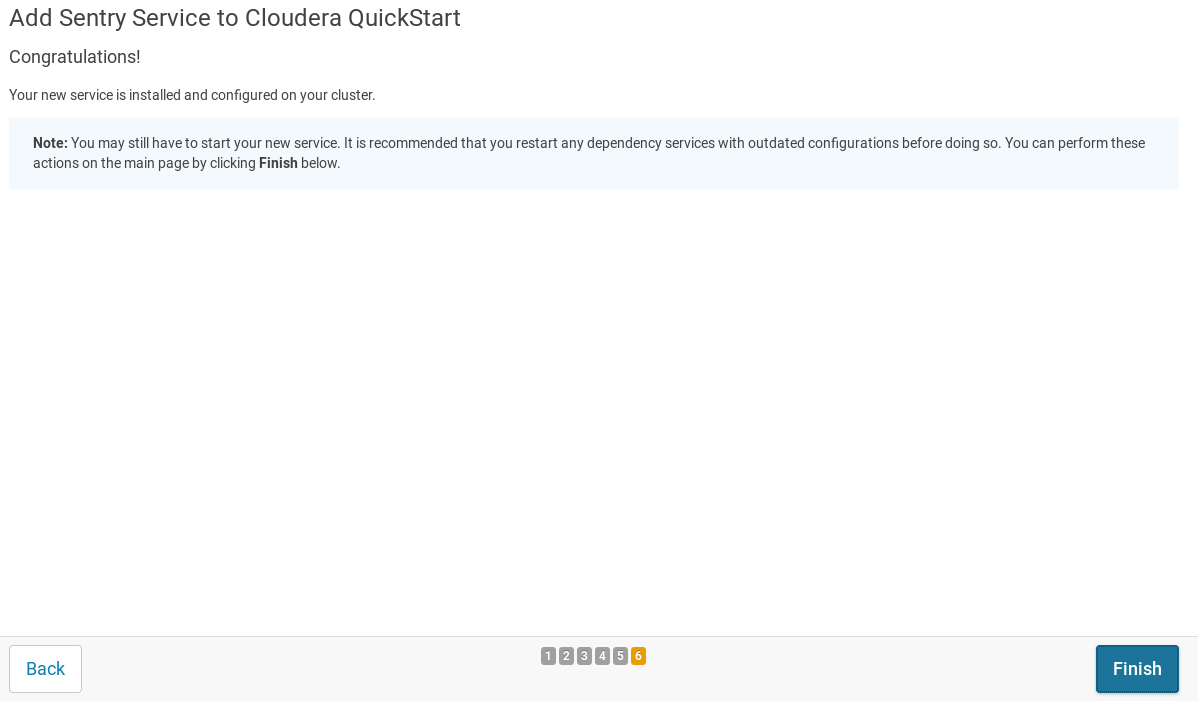
continue等待各个服务重启,全部完成后点击continue,之后点击finish完成sentry服务的添加;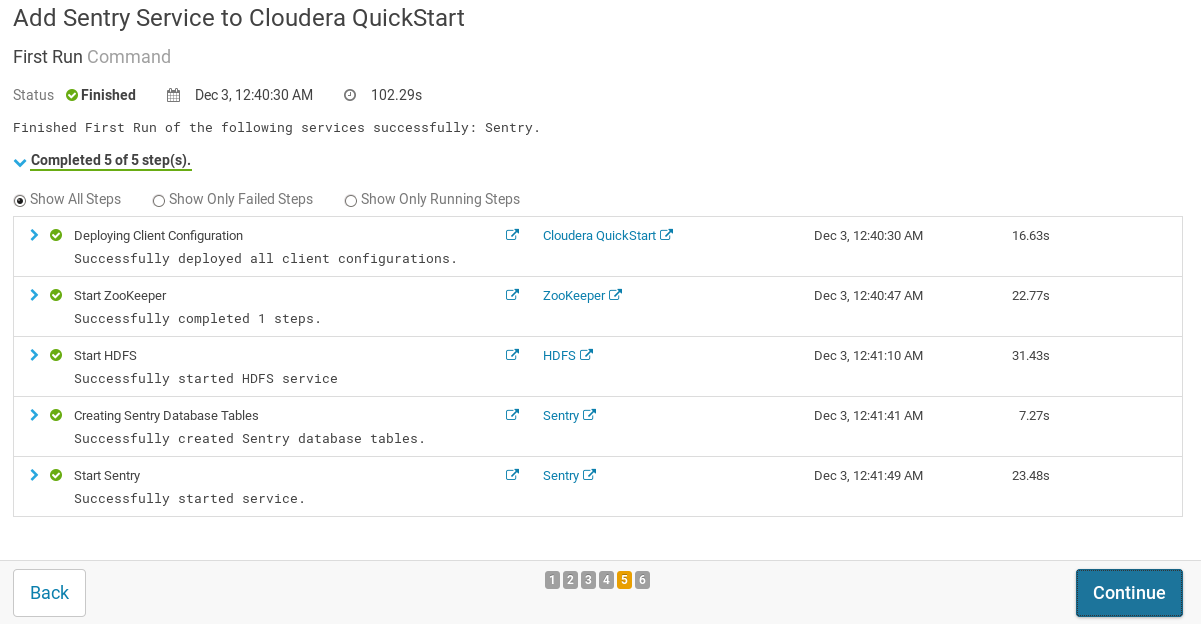
配置Hive
进入浏览器中Cloudera Manager主界面,点击左侧栏的
Hive。进入Hive设置界面后点击左上角的Configuration,在下方界面的Search输入sentry,并将Sentry Service选项修改为Sentry;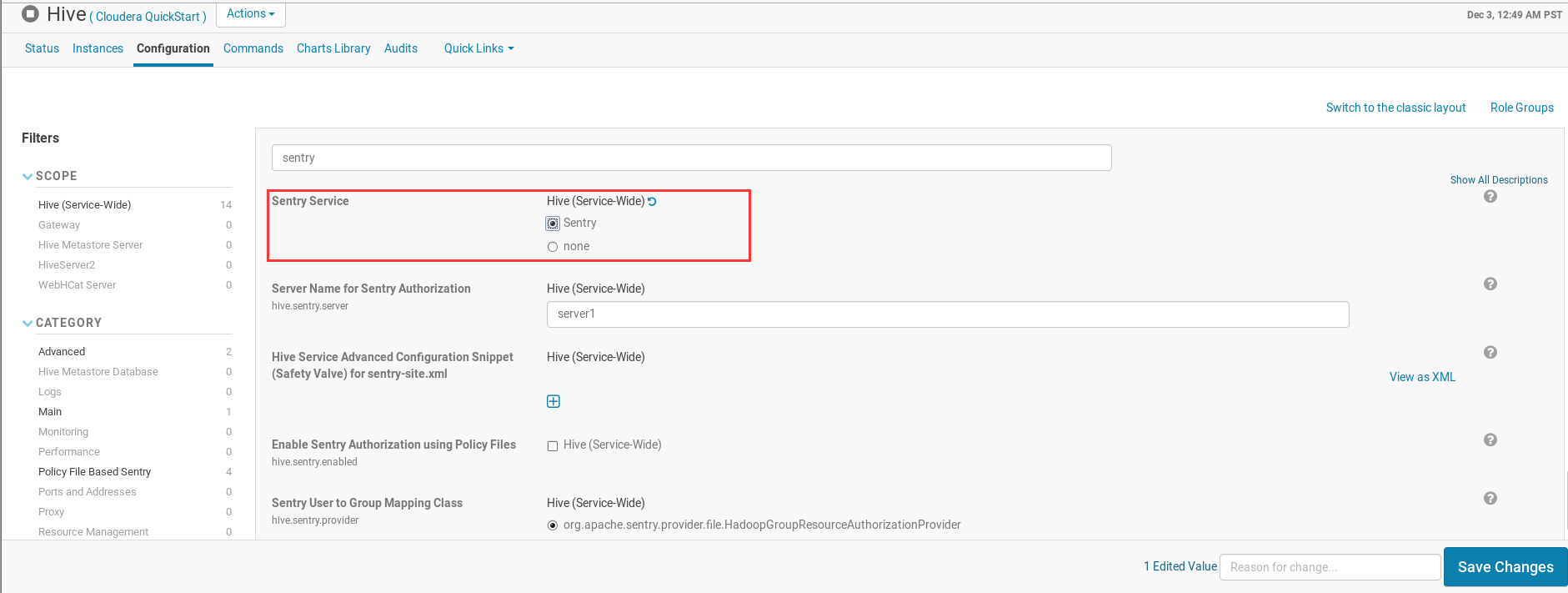
之后在Search输入
imper,取消Impersonation的相关选项;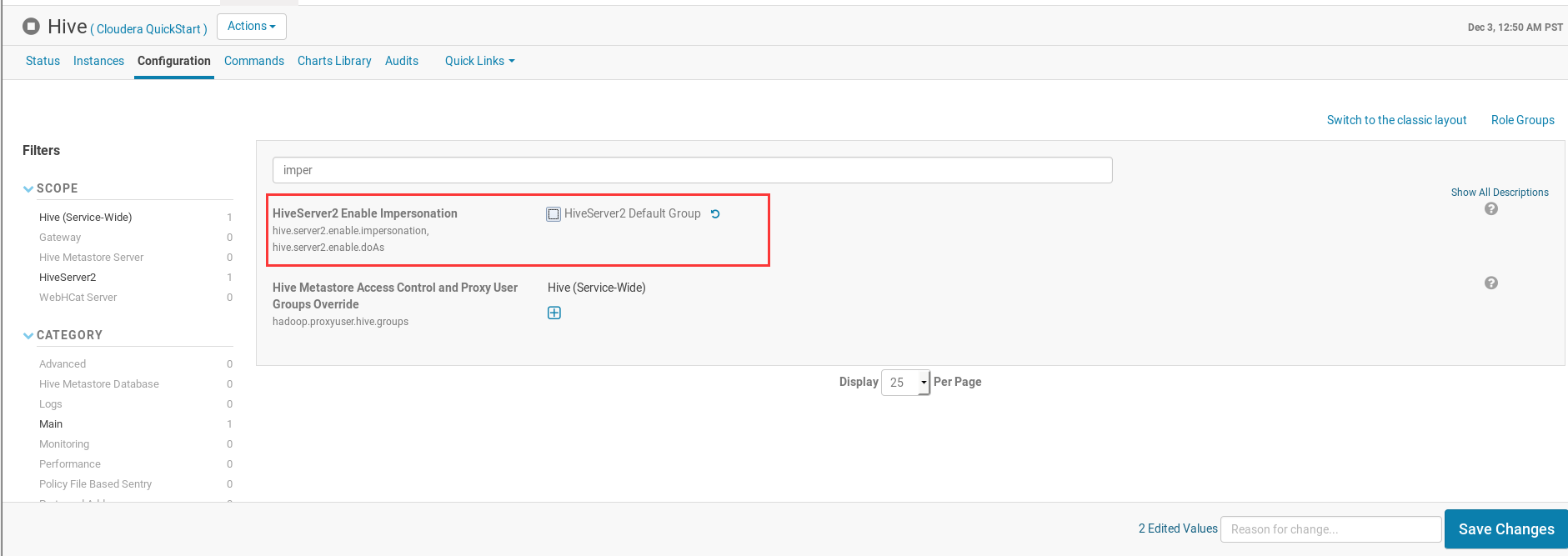
完成后在Search输入
sentry-site,点击加号添加sentry.hive.testing.mode键并将值设为true;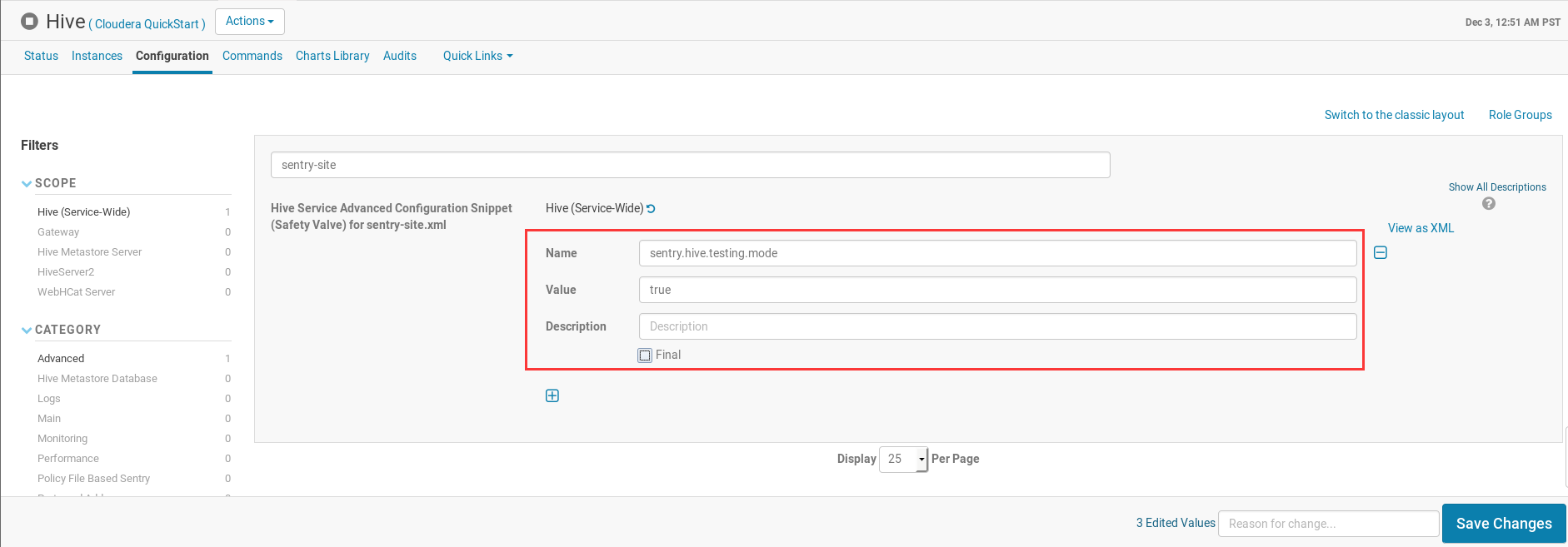
之后点击
Save Changes,并回到主界面,点击左侧新出现的红色扳手;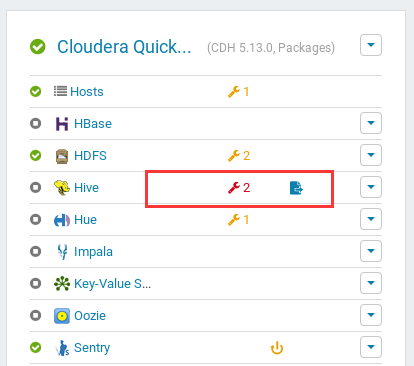
弹出窗口后点击
Enable Stored Notifications in Database,勾选相关选项并点击Save Changes保存配置,然后点击右侧的蓝色文件图标提交修改的配置文件并重新启动所有相关服务;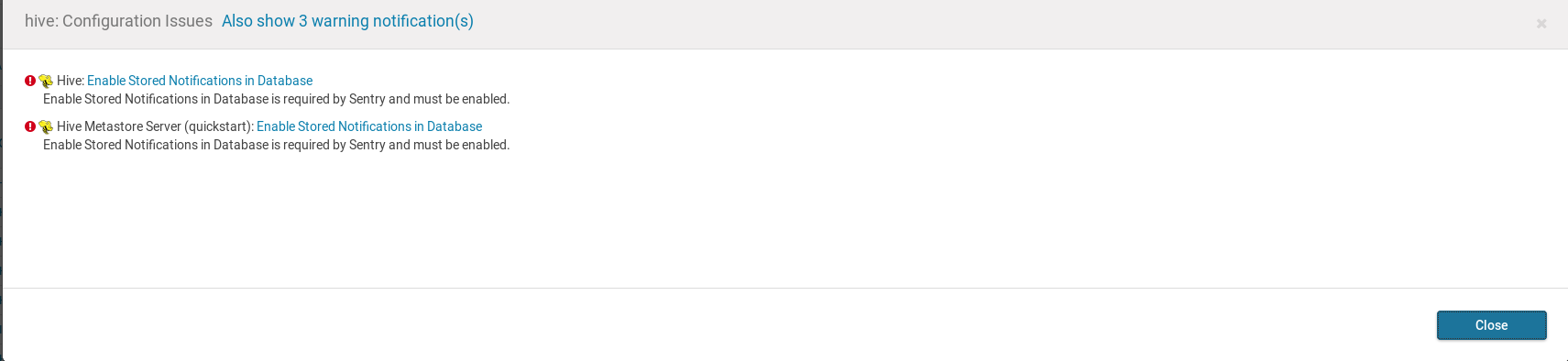

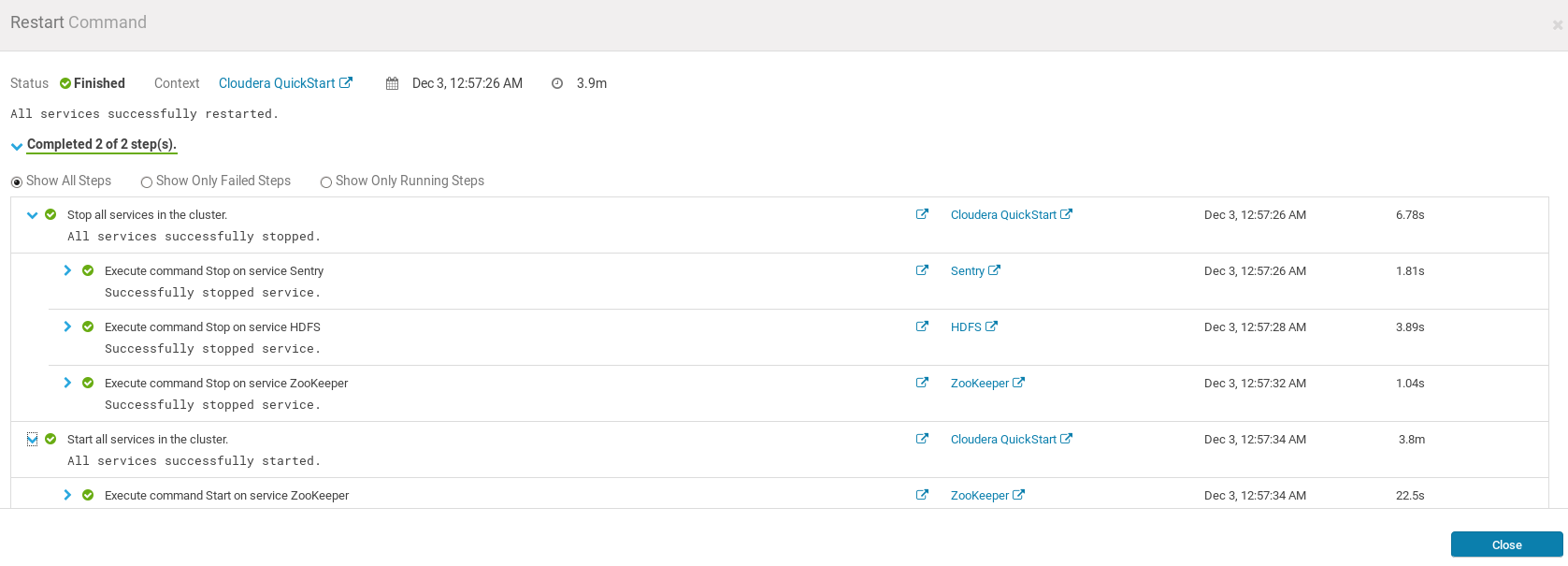
重启后进入主界面,重启虚拟机,并再次运行桌面上的cloudera express,进入浏览器等待程序运行完毕,登录cloudera manager,点击左侧栏的蓝文件图标更新配置文件并重启到如下状态开始相关实验;
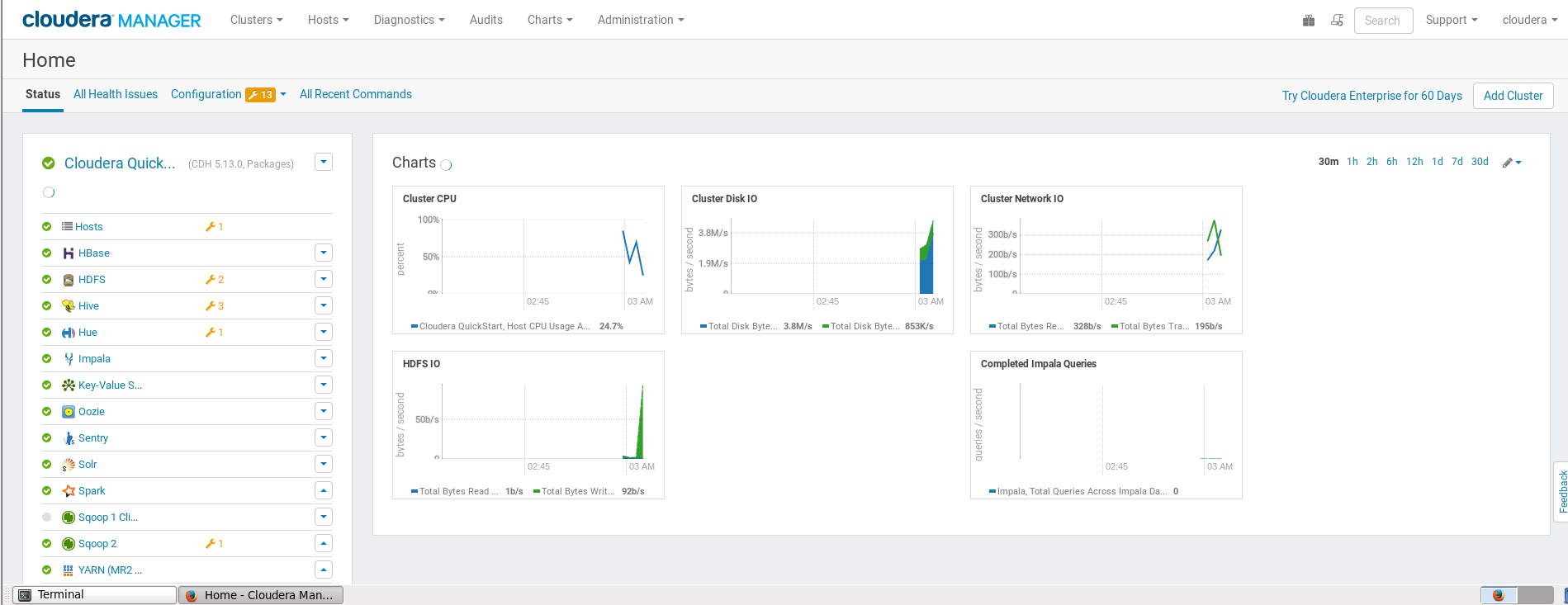
实验数据库搭建
打开终端,输入
beeline打开beeline命令行终端。进入beeline后输入!connect jdbc:hive2://localhost:10000链接数据库,用户名为hive,密码为空;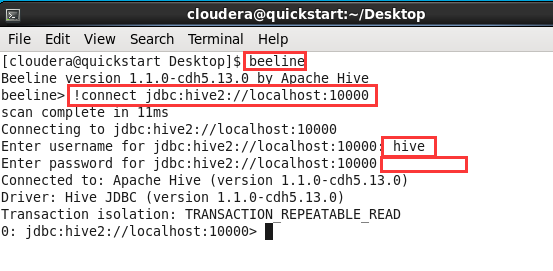
输入命令
create role admin_role;创建管理员角色;
通过命令
grant all on server server1 to role admin_role;赋予其对server1(系统中的服务器名称)服务器的所有操作权限;
通过
grant role admin_role to group hive;命令将admin_role拥有的权限添加到hive组中;
关闭当前终端,再次使用hive登录系统执行如下操作:
输入
create database school;创建school数据库;
输入
use school;切换到school数据库;
输入
create table gradebook(id string, first string, last string, grade int) row format delimited fields terminated by ',';‘创建gradebook表,该表包含id、first、last和grade列;
输入
insert into gradebook values('10001','san','zhang',80),('10002','si','li',90);插入两条数据,该过程较慢,需等待片刻;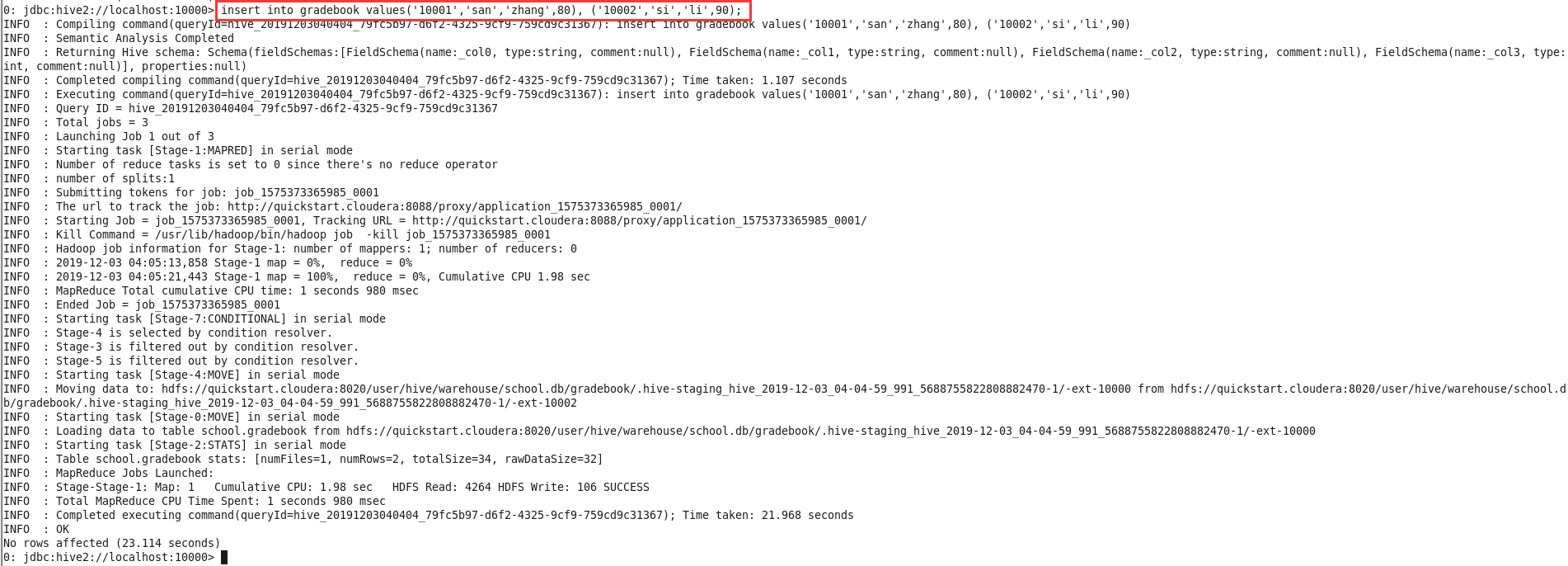
输入
select * from gradebook;确定数据有正确插入到数据库中;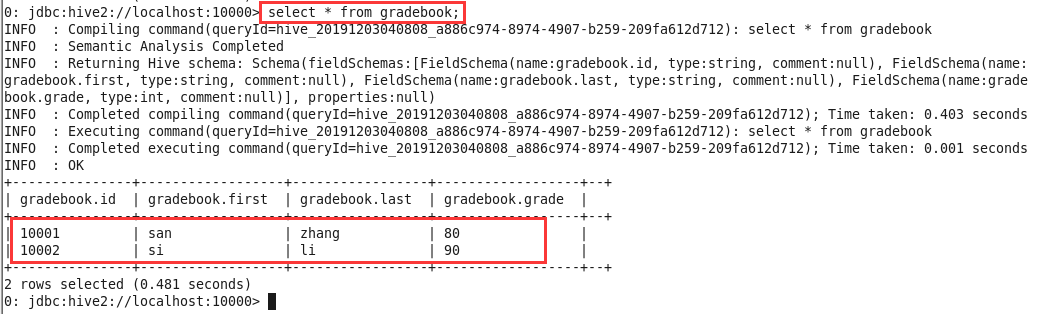
权限分配
打开新的终端,输入
sudo useradd student、sudo useradd grader,分别创建一个student用户和grader用户,并通过sudo passwd student、sudo passwd student设置密码;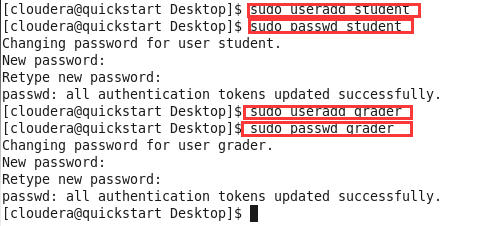
回到beeline终端,输入
create role student_role;创建新角色;
输入
grant select (id,first,last)on table gradebook to role student_role;使student_role只能读取gradebook表的id、first、last列;
输入
create role grader_role;创建新角色;
输入
grant insert on table gradebook to role grader_role;使得grader_role只能插入数据到gradebook表中;
输入
grant role student_role to group student;将student_role的权力赋予给student组;
输入
grant role grader_role to group grader;将grader_role的权力赋予给grader组;
权限测试
重新打开一个终端并启动beeline,输入
!connect jdbc:hive2://localhost:10000后回车,用户名为grader,密码为空登录该用户;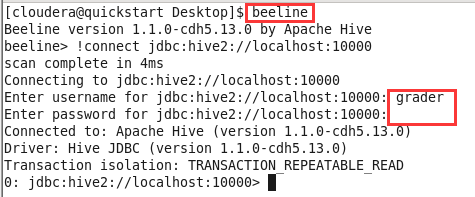
输入
use school;选择school数据库;
输入
select * from gradebook;,确认grader没有权力查看该表;
输入
insert into gradebook values('10003','wu','wang',100);将数据插入到表中;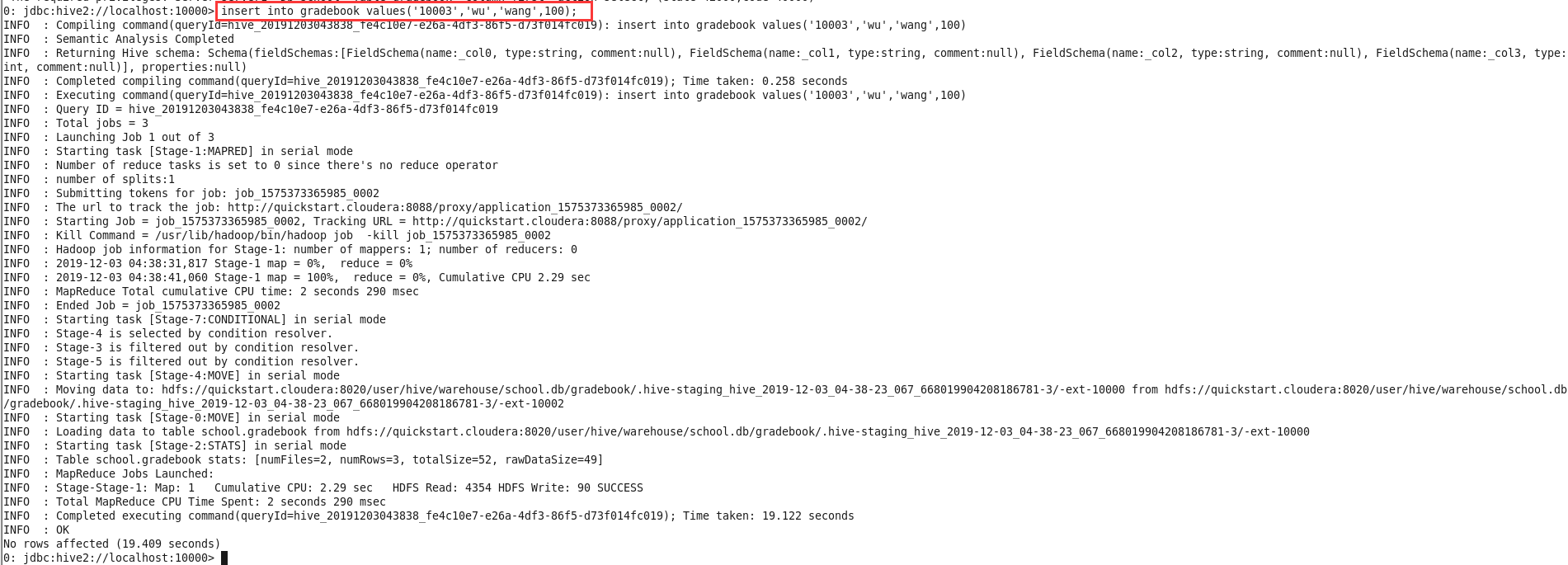
由于grader无权查看数据,新建终端启动beeline,以hive的身份进入数据库,输入
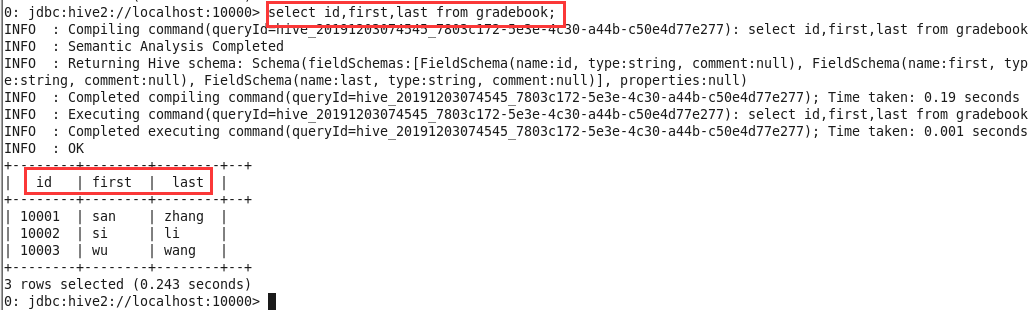
use school;切换数据库并输入select * from gradebook;,根据下图显示,确认grader的数据正确插入到数据库中;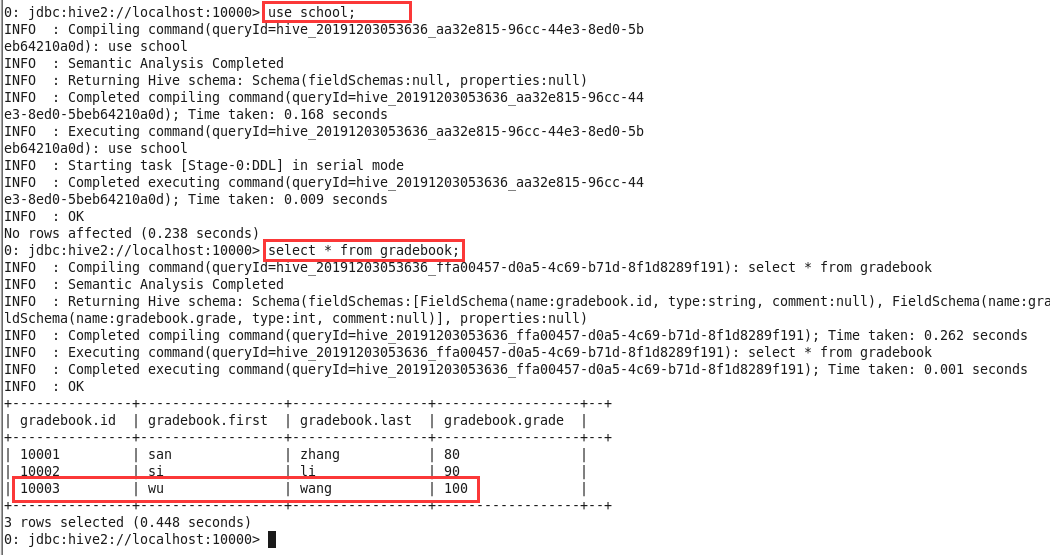
退出该终端,启动新终端进入beeline,以student的身份登录系统。输入
use school;切换数据库并输入select * from gradebook;发现student是否可以查看gradebook的全部数据;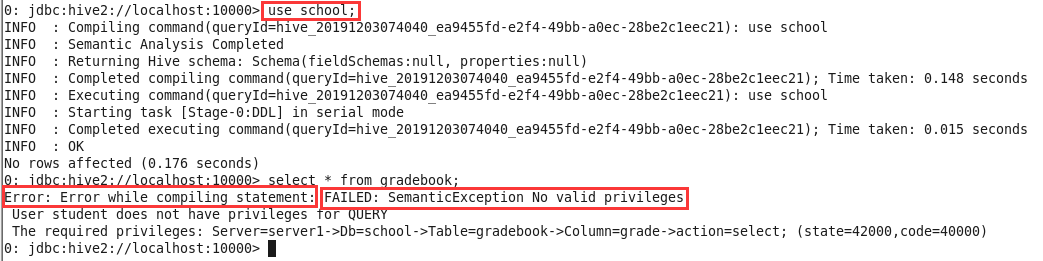
输入
select id,first,last from gradebook;确认student可以查看已授予查看权限的id、first、last列;